Application-Aware Routing (AAR) with SD-WAN
By Christopher Schelmety, Senior Network Engineer, Marcum Technology
 with SD-WAN")
It’s Monday morning, 7:34 a.m. As you sit in traffic sipping your coffee and watching your GPS estimated arrival time slowly move closer and closer to your 8 a.m. start, panic begins to set in. You should be walking through the door with plenty of time to spare, but the trail of taillights before you is about to make that an impossibility.
Then, an alert from your GPS app: A faster route has been found!
After a careful exodus from the left lane, you take the next exit and find yourself free and easy on some back road you’ve never heard of and will probably never see again. As you pull into your parking spot at 7:55 a.m., you marvel at the power of these 21st-century devices to help with even the smallest of daily tasks.
As entertaining it is to imagine a team of engineers huddled around a computer screen to calculate a better route around our traffic jam, your GPS app’s functionality really comes down to two factors: an insanely large pile of data and the automated analysis and execution of that data.
Although the modern enterprise’s network doesn’t operate at the scale of Apple or Google’s dataflows, the concept is the same: We strive to compile data about our network infrastructure performance, analyze that data, and make decisions and actions that are not only intelligent, but also programmatic and efficient.
What is SD-WAN?
To begin, let’s break down this ubiquitous acronym into its two parts: software-defined (SD) and wide area network (WAN).
The concept of software-defined networking (SDN) has been around for some years now. At its most basic, it is an abstraction of the control and management plane from the physical devices handling the data plane traffic. Instead of separate devices to provision and manage, SD-WAN allows for a unified view of the entire network. That enables centralized network management, orchestration, and security.
Continuing our traffic analogy, imagine if each town on your route only had knowledge of its own roadways. You would essentially need a separate phone app for each area. Even worse, you would need to continuously switch between apps as you drove from town to town, and each app would provide varying levels of performance and efficiency. Abstraction and aggregation of each town’s data allow for a unified experience in one app that has visibility of the entire route.
SDN allows us the same flexibility with our network devices. We can move away from disparate network devices that make independent decisions with limited knowledge of the environment, and towards an intelligent and integrated controller.
The wide area network (WAN) is the physical and logical connection of these network devices. Given the infinite requirements and limitations of enterprise networks around the globe, there will never be one design or solution to fit them all. However, a general network architecture usually consists of one to two data center locations, a large headquarters location, numerous smaller branch offices, and cloud infrastructure (Amazon AWS, Microsoft Azure, Google Cloud Platform, etc.). Enabling communication between these physically disparate locations in an intelligent, programmatic, secure, reliable, and, ideally, automated manner is the overarching goal of SD-WAN.
So how do we do it?
Traditional WAN
To see where we’re going, we will begin with a look at traditional WAN architecture. For simplicity, we will focus on a single branch site with multiple paths back to our data center.
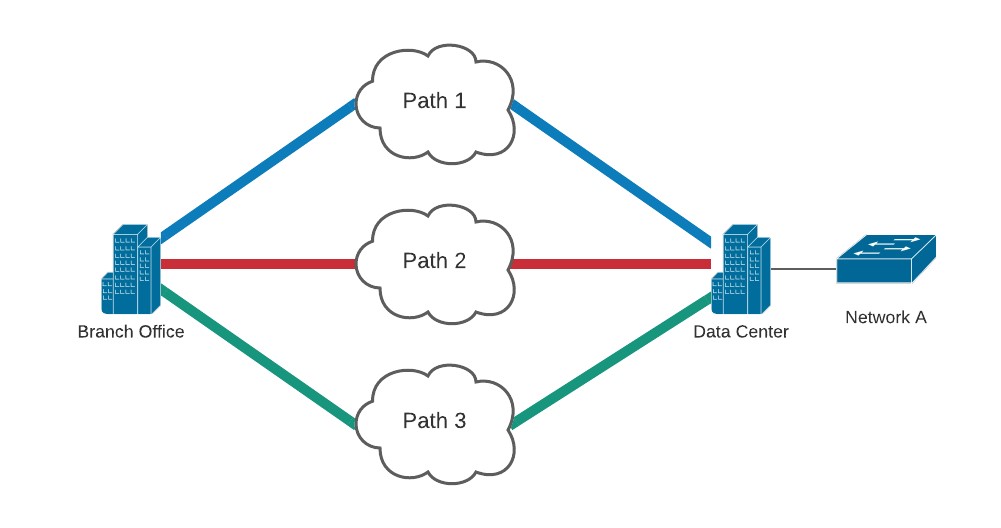
In the example above, we have destination network A. To decide which path to take, the branch office WAN router will consider from which interfaces it is learning about network A, the metrics of our dynamic routing protocols, and our static configurations on the router. There is a plethora of elements that go into a routing decision, and plenty of ways to break the rules — but for our purposes, the three main issues are as follows:
- Routing decisions are based on network locations (IP addresses), not the characteristics of the traffic itself. Traffic destined to network A could be low-bandwidth, latency-sensitive voice traffic, or a custom application requiring high bandwidth. The routing decision will be the same for both.
- Each physical path has different characteristics — bandwidth, latency, jitter, loss, QoS capability, etc. Our routing options could include an MPLS link with full QoS and carrier redundancy, but low bandwidth mixed with a large internet circuit that is insecure and relatively unreliable. These differences are not considered at this routing level.
- Routing protocols will have mechanisms to recover from a link going full down by reconverging once a neighbor is lost. We can, however, have a situation where the link is still up but with degraded performance. There is no inherent or robust way for the routing protocol to understand the quality of the link selected. For that reason, we could end up selecting a path that works poorly over one that is healthy.
SD-WAN
SD-WAN allows us to improve on the limitations of these three issues. Using the SDN concepts discussed previously, we can abstract the routing decisions from the physical architecture of the network. The layout and connectivity of this physical architecture refers to our “underlay” network. A centralized controller with a complete picture of this underlay network chooses which path the traffic can follow. Our “overlay” network, then, is a logical representation of these decisions, and is separate from the physical characteristics of our underlay network. In our diagram above, our overlay will be a single path from our site to our data center hosting network A, regardless of which underlay or physical path is taken.
The best example and use case is connectivity to cloud services. Traditionally, this was achieved by either private physical links through a third-party carrier or by communication over public internet using encrypted virtual private network (VPN) tunnels. Both options typically terminated in a centralized data center location, and all traffic to and from the cloud environment needed to be backhauled through the data center. This architecture was favored as the costs of implementing the physical infrastructure for private direct links or VPN tunneling at every branch location was usually prohibitive.
This isn’t always an issue and may even be preferred by some enterprise organizations. However, SD-WAN offers us more flexible options for connectivity. Most cloud providers now have the means to extend an SD-WAN network into their environments. This allows a direct overlay connection into the cloud environment from our branch and remote locations. Because this overlay traffic is encrypted and secure, routing over the public internet direct from the branch location becomes a possible, if not preferred, selection for our underlay routing.
Application-Aware Routing
But have we resolved any of the issues from traditional WAN routing we previously mentioned?
Although we have centralized the routing decisions on our network, our controller is still calculating its underlay routing based on network location and IP addresses. We haven’t introduced any understanding of the characteristics of our physical links, or real-time analysis of the current network conditions.
Cisco’s SD-WAN solution for this is called “application-aware routing,” but most SD-WAN vendors offer the same functionality with different names and features. The basic functionality and uses remain the same, however, and this article will utilize the Cisco terminology.
Our first step is to define our applications. This can be done by IP addresses and networks, like our traditional WAN model, or by the characteristics of our application sessions, including protocol, port numbers, and QoS markings. Within our SD-WAN controller, we also have pre-defined applications that utilize all the above, plus deeper application layer details.
Once we’ve defined our applications of interest, the next step is gaining an understanding of current network conditions. This is accomplished using bidirectional forwarding detection (BFD). Devices on each end of a physical connection become BFD neighbors and start sending BFD packets. These packets are sourced from a device’s interface address and destined to that same address. After it is sent over our link and received on the other end, it is sent back to the originating device. In this way, we can get information on the link’s performance. The number of packets we don’t receive back give us the loss percentage of the link. The amount of time it takes for the packet to return to us measures the link’s latency. This data is aggregated at our SD-WAN controller, and represents real-time information about our physical infrastructure.
Our final step is to determine when a path can be used and for which applications. We create service-level agreement (SLA) classes that define the minimum acceptable performance for a path to be added to that class. Our paths’ measurements are then averaged, and each are included in all SLA classes that meet the minimum requirements. Lastly, we create our AAR policy that includes our application identification, preferred path in normal conditions, and SLA class to provide acceptable fallback paths.
Example of AAR

Using our network diagram, we have a latency-sensitive application that communicates between our site and network A, and three paths to get there: blue, red, and green. We have loss, latency, and jitter metrics for each of these links, and we know that our application will have degraded performance over 100 milliseconds of latency. Blue will be our preferred path, but we can use red or green if needed.
We create an SLA class called “our application” that sets the latency threshold at 100 milliseconds. We then create our AAR policy that identifies our traffic, selects blue as the primary path, and calls the “our application” SLA class. This is then specifically applied to the blue, red, and green paths running between our two sites.
When the latency of the blue path reaches more than 100 milliseconds, our edge devices are aware of red and green as secondary paths depending on the blue path’s latency measurements. Of course, if red or green are not meeting our latency requirement, they would not be used either. And if all three do not meet our latency requirement, we have a static path selection configured as last resort. We’d rather have degraded performance than no performance at all.
Conclusion
This is how we resolve the three shortcomings of traditional WAN routing we discussed earlier. Our route selection is no longer exclusively tied to network IP addresses and can rely on the characteristics of the traffic itself. We have the intelligence to understand the details of each of our paths and use that data to make decisions appropriately. Finally, network failover no longer requires full failure of a network link; instead, it can be based on real-time measurements taken from the physical links, and comparison of these against our acceptable thresholds. Back to our car traffic analogy, the centralized data of our SD-WAN environment can now direct our traffic around roadblocks and accidents to arrive at work on time. Furthermore, we have knowledge of the vehicle being driven. Just as we would require our navigation to avoid sending an 18-wheeler down a road with low clearance or narrow lanes, modern SD-WAN solutions can route appropriately based on traffic characteristics and current network conditions. The application-aware routing features of SD-WAN give us that capability.
Understanding an SD-WAN solution is not an easy task. Here at Marcum Technology, we have experienced consultants who are ready to engage throughout the entire process. For more information, contact [email protected] #AskMarcumTechnology


















